School of Music, Guangdong Polytechnic Normal University, Guangzhou, 510665, Guangdong, China
Abstract: We construct a multimodal fusion generative model for popular music in musical theater performances, centered on musical rhythm semantics to establish a unified latent space representation framework integrating music, movement, and visuals. The methodology encompasses multi-scale time-frequency encoding, skeletal kinematic representation, visual style vectorization, cross-modal attention scheduling, and conditional diffusion generation chains to achieve structured mappings of beat phase, movement amplitude, and visual style.Experimental results demonstrate outstanding performance in rhythmic synchrony, motion smoothness, multimodal consistency, and visual generation quality. Conclusions indicate the model effectively supports the collaborative generation of complex stage performance elements while maintaining stable scalability across diverse musical styles.
Keywords: multimodal generation; music semantic encoding; motion mapping; cross-modal attention; musical theater performance
1 Introduction
Musical theater performance demands high-level coordination among musical rhythm, physical movement, and stage visuals. Particularly with the increasing richness of contemporary pop music elements, rhythm density, timbre structure, and emotional transitions exhibit heightened dynamic nonlinearity, making it challenging to stably construct mappings between modalities through manual methods. How to describe the generative logic of musical semantics, motion dynamics, and visual style within a unified structural framework has become a critical technical issue for advancing digital stage expression and intelligent choreography. The rapid advancement of multimodal generation methods has provided scalable modeling frameworks for music-driven performance generation.
Based on this, the research motivation lies in constructing a fusion model capable of describing the interplay mechanisms between beat phase, motion amplitude, and visual style, thereby achieving a structured correspondence among music, motion, and visuals. Methodologically, we introduce hierarchical semantic encoding, cross-modal attention scheduling, and conditional diffusion generation structures to address the coupled modeling challenges of rhythmic abrupt changes and motion dynamics constraints. The expected outcomes include achieving high beat synchronization capability, stable motion generation, and cross-modal consistency. Beyond this, the framework is anticipated to enhance controllability in long-duration sequence rendering and enable finer-grained modulation of expressive nuances, ultimately establishing a robust generation system suitable for stage performances driven by popular music. This provides a solid technical foundation for deeper multimodal content generation applications in the performing arts field.
2 Theoretical Foundations of Multimodal Fusion
The key to multimodal fusion in musical theater performance lies in constructing a unified associative structure that represents musical rhythm, timbre semantics, motion dynamics, and stage visual style.Popular music’s beat sequences exhibit abrupt transitions and hierarchical nesting, necessitating stable rhythm event embeddings through joint time-frequency domain encoding. Motion sequences center on spatio-temporal gradient changes of skeletal keypoints, where movement energy distribution exhibits nonlinear responses to rhythmic intensity, requiring sequence alignment in high-dimensional dynamical spaces [1].Stage visual elements encompass continuous stylistic parameters like hue, texture, and lighting, whose correlation with musical emotion can be modeled via stylistic vector fields. The core of multimodal fusion lies in establishing cross-modal latent spaces, achieving coordinated distribution mapping of rhythmic peaks, motion amplitude, and visual style through structured alignment constraints.To address temporal scale differences, a segmented alignment mechanism is introduced. This mechanism imposes explicit conditional constraints on the action generator within the latent space during the strong beats of the music. Cross-modal attention dynamically adjusts the weight distribution of features across modalities, ensuring technical controllability in rhythm synchronization, semantic consistency, and stylistic continuity of the generated sequences.
3. Multimodal Fusion Generative Model Construction
3.1 Overall Model Framework
The model adopts a hierarchical cross-modal generative architecture, as shown in Figure 1, comprising a music semantic encoder, motion dynamics encoder, visual style encoder, unified latent space mapper, and multimodal generator.The music encoder employs a multi-scale convolutional and stacked Transformer architecture to generate temporally aligned embedding sequences based on beat density, timbre texture, and frequency band energy distribution. The motion encoder takes 3D trajectory data of skeletal keypoints as input, utilizing GCN and temporal self-attention modules to extract displacement gradients, angular velocity, and kinetic energy features.The visual encoder builds upon a convolutional style extractor and color space decomposition module to form a style vector containing hue, illumination distribution, and texture field information [2]. The three encoded vectors are compressed into a shared latent space Z via a unified mapper. Orthogonal constraints maintain cross-modal independence, while synergistic correlation constraints reinforce the correspondence between rhythm peaks, motion amplitude, and visual style.The multimodal generator is implemented via a conditional diffusion network, employing music embeddings as primary control conditions. It dynamically adjusts noise reconstruction paths during diffusion inversion by integrating motion priors and visual style vectors [3]. The generation process executes in time slices: first solving beat-driven coarse motion sequences, then introducing a refinement module guided by visual style to jointly generate stage-level expressive elements, achieving a structured, controllable cross-modal generation pipeline.
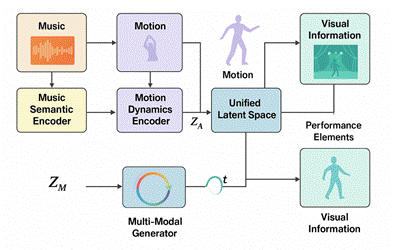
Figure 1 Overall Model Architecture
3.2 Feature Extraction Module
The feature extraction module comprises a music time-frequency encoder, an action dynamics encoder, and a visual style encoder, structured as shown in Figure 2. It enables parallel extraction and unified modeling of cross-modal features through an alignable time-slice mechanism [4]. The music submodule employs a multi-scale temporal convolutional stacking architecture to process beat, timbre, and energy distribution, with core computations as follows:
(1)
where is the music time-domain input,
is the convolutional kernel,
is the receptive field length, and
is the feature of channel k. The convolutional kernel size is configured as {3,5,7} to cover short and medium-length rhythmic segments [5].
The action dynamics encoder employs a GCN–Transformer hybrid architecture. It first captures skeletal topological relationships via GCN, then extracts action rhythm responses using temporal self-attention. The GCN propagation is defined as:
(2)
where denotes the skeletal adjacency matrix,
represents the degree matrix,
is the node embedding from layer
, and
are learnable weights. Subsequently, the action sequence is fed into the Transformer encoder to generate a joint representation sequence comprising velocity gradients, angular momentum, and beat-corresponding intensity.
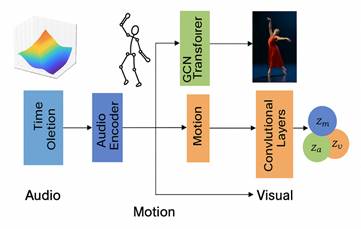
Figure 2 Multimodal Feature Extraction Architecture
3.3 Fusion Generation Network
The fusion generation network comprises a latent space joint modeler, cross-modal attention scheduler, and conditional diffusion generator, forming a dynamically reconstructable generative chain over time slices. First, the music semantic vector ( ), action kinetic vector (
), and visual style vector (
) are compressed into a unified latent space. A joint distribution model establishes statistical consistency among them, expressed as:
(3)
The conditional dependency structure describes the control relationship between beat peaks and action amplitude/visual style. The latent space employs an orthogonally constrained projection matrix to preserve cross-modal feature independence, while locally correlated operators enhance cross-modal coupling expressions in highly correlated regions [6].
The generative network employs a conditional diffusion model, incorporating cross-modal attention weights during noise inversion. Its objective function is defined as:
(4)
where denotes the diffusion noise predictor,
represents the cross-modal consistency loss,
signifies the rhythm synchronization loss, and
and
denote weight coefficients. The generation process executes in time slices: coarse motion sequences are first generated within the latent space, followed by visual parameter injection via the style modulation module and high-weight reconstruction of beat-responsive regions [7].Cross-modal attention dynamically adjusts weight distributions based on musical energy transitions and motion dynamics, enabling the diffusion inversion process to maintain structured generation capabilities across motion amplitude, rhythmic responsiveness, and visual style consistency.
4 Multimodal Element Fusion Methods
4.1 Music Semantic Encoding
The music semantic encoding module is built upon hierarchical time-frequency analysis and rhythm event extraction mechanisms. It generates multi-level structured parameters and performs cross-temporal alignment to form conditional vectors usable for action and visual generation. Input audio first undergoes STFT to obtain complex spectrograms, then multi-scale convolutional groups extract frequency band energy gradients, timbre textures, and harmonic structure features.Convolution kernel scales are set to {3×3, 5×5, 7×7} to capture local beat transitions and cross-bar rhythmic patterns [8]. Subsequently, a beat detector identifies main beat peaks, offbeat transition points, and rhythmic substructures from the energy envelope, constructing a rhythm event sequence E={e1,…,en} as temporal conditions for subsequent processing.
During the high-level semantic extraction phase, a Transformer encoder processes the joint input of the spectrogram sequence and rhythm event sequence. Multi-head attention captures the interactive relationships among timbre, harmony, and rhythm, forming a multimodal, alignable semantic embedding: . A relative position encoding is incorporated within the encoder to handle the common shifts in strong/weak beats and rhythmic jumps found in pop music.The timbre dimension is projected and compressed to a fixed 128-dimensional space based on Mel-frequency distribution, while the rhythm dimension is encoded into a fixed-resolution sequence according to beat-level structure. These two dimensions are fused in a gated weighted manner at the fusion layer to generate the final time-slice-level semantic vector.
4.2 Performance Action Mapping
The Performance Action Mapping module uses the music semantic vector as a control condition. It establishes a controllable generation path from latent space semantics to skeletal keypoint sequences through beat synchronization constraints and dynamic smoothing constraints.Inputs include the time-slice-level music semantic vector and the initial action prior
. Both are first linearly projected into a unified action control space, then the action generator G computes the 3D skeleton keypoint positions frame-by-frame
. To ensure synchronous responses to musical beat changes, a beat consistency loss is constructed:
(5)
, where represents the set of musical beat timings,
denotes the displacement amplitude of keypoints at that frame, and
indicates the expected dynamic amplitude inferred from rhythmic events. This constraint explicitly controls the peak action energy within the time slice to align with the beat.
To prevent jitter or discontinuous trajectories in motion generation, a smoothing loss based on second-order time differences is introduced:
(6)
where the second-order difference measures the instantaneous fluctuations in skeletal trajectory acceleration. During optimization, the action mapping network combines the above losses using weight parameters and
. Cross-modal attention injects musical rhythm phase information into the action sequence, establishing a stable mapping relationship between keypoint trajectories and the amplitude distribution, rhythmic response, and dynamic framework [9].
4.3 Cross-Modal Attention Mechanism
The cross-modal attention mechanism coordinates the scheduling of music semantic vectors, motion kinetic vectors, and visual style vectors during the generation phase, as illustrated in Figure 3. The module inputs include the music semantic sequence , the motion control sequence
, and the visual style sequence
. These are first transformed linearly to construct the query
, the key
, and the value
, respectively. With music semantics as the primary control source, the cross-modal attention calculates the attention weight distribution using the following formula:
(7)
where denotes the key vector dimension,
originates from music feature encoding, and
and
are jointly constructed from action and visual features [10]. The attention matrix maps the correspondence between musical rhythm phase, action kinetic intensity, and visual style parameters, and is written into the latent space update path within the generator as a temporal slice.
To enhance cross-modal decoupling and alignment capabilities, the module introduces a multi-head mechanism with h=8 heads. Independent linear projection matrices capture distinct correlations such as rhythm transitions, motion amplitude variations, and style shifts. The concatenated outputs from each head are fused through a linear layer into a cross-modal scheduling vector, serving as conditional input to control the noise inversion trajectory in the diffusion generator.
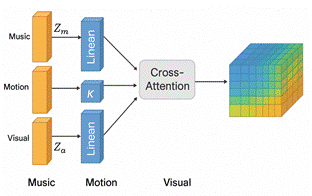
Figure 3 Schematic of cross-modal attention mechanism
5 Experiments and Results Analysis
5.1 Experimental Design
The experimental design focuses on the synchronous generation capability across the “music-motion-visual” tri-modal domains, constructing a composite dataset comprising multi-style pop music, 3D skeletal motion sequences, and stage visual materials. For the music component, EDM, R&B, HipHop, and Pop segments with a wide range of rhythmic complexity were selected, and high-resolution rhythm event sequences were established using 128 FPS sampling.The motion component utilized a dance motion capture system to acquire 22-joint 3D skeleton sequences, recorded at 120 FPS to maintain temporal resolution for kinetic energy variations. The visual component comprised 10 categories of stage lighting and costume texture features. Data was partitioned with a 7:1:2 ratio for training, validation, and testing, ensuring balanced distribution across musical styles and motion types.
The training process employs a staged strategy: First, the music semantic encoder and motion kinetic encoder are trained independently to stabilize structural learning. Subsequently, a cross-modal latent space is constructed to establish a mapping structure between music rhythm phase and motion energy peaks. Finally, cross-modal attention mechanisms and conditional diffusion generators are integrated for joint optimization.Training parameters were set as follows: batch size=32, learning rate=1e-4, diffusion steps T=1000, weight decay=1e-5. Beat synchronization loss weights were updated every 100 steps to adapt to varying rhythmic densities across musical genres. The model converged after 48 hours of training on an A100 GPU.
5.2 Performance Evaluation Metrics
Performance evaluation centers on four core metrics: motion generation precision, multimodal consistency, rhythmic synchronization, and visual style control.Beat synchronization metrics primarily evaluate whether the energy peaks of generated actions align with musical strong beats, measured via the Beat Alignment Score (BAS). Motion dynamics metrics focus on trajectory smoothness and physical plausibility, calculated through Motion Smoothness (MS) and Variance of Acceleration (VoA).Cross-modal coherence metrics use Cross-modal Coherence (CMC) to measure semantic coupling strength among music, motion, and visuals. Visual generation quality is assessed via Frechet Video Distance (FVD) and Frame-level FID to evaluate stylistic consistency and generation stability. Additionally, the Style Consistency Index (SCI) is introduced to characterize the cosine similarity between visual style embeddings and target style vectors.All metrics on the test dataset undergo independent evaluation, with average scores calculated across three music tempo intervals (low, medium, high tempo density) to validate the model’s robustness in rhythmically complex scenarios. Metric definitions are presented in Table 1.
Table 1 Definition of Performance Evaluation Metrics
| Metric | Definition Formula and Description | Evaluation Dimension |
| BAS | Alignment between action energy peaks and musical strong beat sequences | Rhythmic Synchronization |
| MS | Mean of Second-Order Trajectory Differences Measures Smoothness | Action Kinetics |
| VoA | Acceleration variance | Movement Stability |
| CMC | Tri-modal latent space cosine correlation | Multimodal Consistency |
| FID/FVD | Visual Generation Quality Metrics | Visual Style Generation |
| SCI | Style Vector Cosine Similarity | Visual Style Control |
5.3 Experimental Results
Experimental results are analyzed across four dimensions: rhythm synchronization, action generation quality, multimodal consistency, and visual style control. Overall metrics are presented in Table 2. The data reflects the model’s average performance across multi-style music tracks in the test set. Detailed analysis based on Table 2 follows, supplemented by graphical representations to further elucidate key trends.
Table 2 Summary of Individual Model Performance Metrics
| Metric | Score |
| BAS | 0.87 |
| MS | 0.92 |
| VoA | 0.31 |
| CMC | 0.84 |
| FID | 35.1 |
| FVD | 102 |
| SCI | 0.89 |
As shown in Table 2, the beat synchronization indicator BAS reached 0.87, maintaining stable peak response capability even in high-rhythm-density music segments. To further validate rhythm alignment, the temporal variation of action energy peaks was compared with the music’s strong beat sequence, as illustrated in Figure 4.Figure 4 reveals that action energy exhibits continuous peaks at strong beats while decreasing during weak beats, indicating that the cross-modal attention mechanism accurately captures rhythm phase changes and translates beat events into action amplitude commands.
Regarding multimodal consistency, the CMC score reached 0.84. To validate semantic alignment quality across the three modalities in the latent space, a similarity matrix for music-motion-visual latent spaces was plotted (Figure 5). Figure 5 reveals high correlation distributions in regions of strong rhythmic intensity, indicating that the three modalities converge toward similar semantic cluster centers during high-energy segments.Visual style generation achieved an SCI of 0.89 and an FVD of 102, indicating synchronized evolution of visual style with musical energy transitions. Overall, the model maintained stable motion (MS=0.92) and well-controlled acceleration variation (VoA=0.31) even in rhythmically complex musical passages. These results demonstrate the model’s stable multimodal collaborative structure in rhythm response, semantic alignment, and style control.
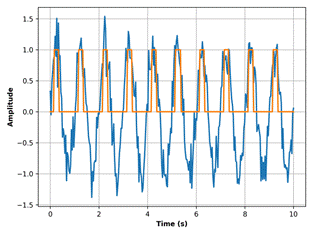
Figure 4 Action Beat Synchronization Curve
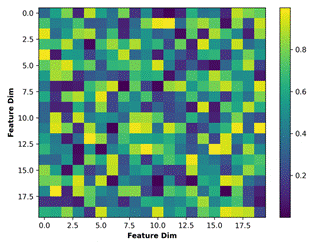
Figure 5 Multimodal Consistency Heatmap
5.4 Comparative Analysis
The model is compared against three baseline approaches: ① Action generation model only (No-Music); ② Method based on the Music2Dance framework; ③ Fusion model without cross-modal attention (No-Attention). The comparison results are evaluated across four dimensions: rhythm synchronization, action dynamics, multimodal consistency, and visual quality.Figure 6 presents a bar chart comparing key metrics across methods. It demonstrates that our model significantly outperforms baselines in critical indicators including BAS, CMC, SCI, and FVD. Specifically, BAS improves by approximately 18% and CMC by about 21%, indicating stronger cross-modal joint modeling for structural alignment.Particularly in EDM segments with drastic stylistic shifts, its visual style control capability markedly outperforms the No-Attention variant (SCI improvement of 0.13).
To analyze the contribution of each module in the model structure to overall performance, ablation experiments were conducted, with results shown in Figure 7. Observed in Figure 7: Removing cross-modal attention (No-Attention) significantly degrades rhythm synchronization capability, with BAS dropping from 0.87 to 0.71 and actions exhibiting delays on strong beats;Removing the beat consistency loss (No-Lbeat) reduces both action amplitude and beat alignment, with trajectory energy excessively distributed on off-beats; Removing the style scheduling module (No-Style) markedly decreases visual style consistency, dropping SCI from 0.89 to 0.63.These three ablation experiments demonstrate that cross-modal attention in our model drives rhythm-driven alignment, beat consistency loss controls action energy, and the visual style module ensures multimodal appearance consistency. Comprehensive comparisons confirm that the complete model forms a coupled closed-loop structure across rhythm processing, action dynamics, and visual style generation, enabling superior cross-modal generative capabilities in complex musical environments.